scrapy入门之创建爬虫项目+scrapy常用命令 |
您所在的位置:网站首页 › run as administrator 命令语句 › scrapy入门之创建爬虫项目+scrapy常用命令 |
scrapy入门之创建爬虫项目+scrapy常用命令
|
windows下载安装scrapy
进入cmd模式,输入:pip install Scrapy 也可以使用:pip install scrapy==1.1.0rc3 来安装对应版本的scrapy 常见问题pip版本需要升级 python -m pip install --upgrade pip 创建一个scrapy 爬虫首先要使用scrapy 来创建一个爬虫项目,在cmd窗口进入用来存储新建爬虫项目的文件夹,比如我们要在“D:\python”目录中创建一个爬虫项目文件: 首先在cmd窗口进入该目录:执行d: 进入D:盘 执行cd python 进入python目录 执行: scrapy startproject 项目名来创建一个scrapy爬虫项目 然后cd 项目名 进入该爬虫项目文件中 然后使用如下命令创建scrapy爬虫 scrapy genspider 爬虫名称 "域名" # 注意:爬虫名字不能和项目名称一致。 例如:创建爬取糗事百科的爬虫 scrapy genspider qsbk_spider "qiushibaike.com" # www不用写接下来我们用这些命令来创建一个scrapy爬虫 爬取的网站是“https://www.gushiwen.org/” 我的目录是:F:\scrapy 打开cmd F: # 进入F:盘 cd scrapy # 进入scrapy目录 scrapy startproject gushi cd gushi scrapy genspider gushi_1 "gushiwen.org" # 创建名称为gushi_1的爬虫
使用pycharm打开如下图所示: guoshi 子文件夹:项目核心目录 scrapy.cfg 文件:是爬虫项目的配置文件 打开guoshi 子文件夹,如下图所示: __init__.py :是项目的初始化文件,包含项目的初始化信息 items.py : 是爬虫项目的数据容器文件,主要来定义我们所要获取的数据。 middlewares.py : 用来存放各种中间件的文件 pipelines.py : 是爬虫项目的管道文件,主要用来对items里面定义的数据进行进一步的加工 settings.py : 是爬虫项目的设置文件 scrapy常用命令使用scrapy startproject 来创建爬虫项目时,可以加上一些参数进行控制: scrapy startproject -h # 调出帮助信息
日志等级常见值 等级名含义CRITICAL发生最严重的错误ERROR发生了必须立即处理的错误WARNING出现了一些警告信息,即存在潜在错误INFO输出一些提示信息DEBUG输出一些调试信息,常用于开发阶段我们将日志等级设置为WARNING scrapy startproject --loglevel=WARNING mypjt3可以通过 --nolog 参数来设置不输出日志信息 创建一个爬虫项目,并且不输出日志信息 scrapy startproject --nolog mypjt4如果想要删除爬虫项目,就直接删除爬虫的项目文件夹即可 scrapy常用命令Scrapy中命令分为两种: 全局命令:不需要依靠Scrapy项目就可以在全局中直接运行项目命令:必须在scrapy项目中才可以运行 全局命令:在不进入scrapy爬虫项目所在目录的情况下运行scrapy -h 在commands下会出现所有的全局命令 (1)fetch命令 fetch命令主要用来显示爬虫爬取的过程 用法: scrapy fetch 网址 例如: scrapy fetch http://www.baidu.com 显示爬取百度首页的过程如果在scrapy项目目录之外使用该命令,则会调用scrapy默认的爬虫来进行网页的爬取。 如果scrapy的某个项目目录内使用该命令,则会调用该项目中的爬虫来进行爬取 scrapy fetch -h 列出 fetch命令的相关参数比如: --headers参数,来控制显示对应的爬虫爬取网页时候 的头信息 --nolog参数,来控制不显示日志信息 --spider=SPIDER参数,来控制使用哪个爬虫 --logfile=FILE参数,来指定存储日志信息的文件 --loglevel=LEVEL参数,来控制日志等级例:通过–headers参数和–nolog参数控制爬取新浪新闻首页(http://news.sina.com.cn)的时候的头信息,并且不显示日志信息 scrapy fetch --headers --nolog http://news.sina.com.cn(2) runspider命令 可以实现不依托scrapy爬虫项目,直接运行一个爬虫文件 例如:我们编写了一个名为 first.py 的爬虫文件 scrapy runspider --loglevel=INFO first.py可以使用此命令直接运行这个爬虫文件,并不需要依托一个完整的爬虫项目,只需要拥有对应的爬虫文件即可 (3)settings命令 可以查看scrapy对应的配置信息 如果在scrapy项目目录内使用settings命令,查看的是对应项目的配置信息, 如果在scrapy项目目录外使用settings命令查看的是默认配置信息。 在我们创建的爬虫项目文件中。有一个名 settings.py 的文件。我们可以在命令行中进入该项目所在目录。 然后使用 settings 命令查看该项目的配置信息。 例如: scrapy settings --get BOT_NAME 查看配置信息中 BOT_NAME 所对应的值 BOT_NAME 可以在 settings.py 的文件中找到从命令行中退出到项目目录以外,然后使用该命令,查看的是默认配置信息。 scrapy settings --get BOT_NAME 查看配置信息中 BOT_NAME 所对应的值 可以看到,scrapy默认的 BOT_NAME值是:scrapybot(4) shell命令 通过该命令可以启动 scrapy 交互终端, scrapy交互终端经常在开发以及调试的时候用的,使用交互终端可以实现在不启动爬虫的情况下,对网站响应进行调试。 同样,在交互终端中,我们也可以写一些python代码进行相应的测试。 比如:使用 shell 命令为爬取百度首页,创建一个交互终端环境,并设置为不输出日志信息。 scrapy shell http://www.baidu.com --nolog在交互模式中可以使用 xpath 表达式进行网页信息的提取。 我们可以使用 exit()命令退出交互终端。 (5) startproject 命令 主要用于创建爬虫项目 (6)version 命令 通过该命令可直接显示scrapy的版本信息 scrapy version scrapy version -v 查看与scrapy相关的其他版本的信息(7)view 命令 可以通过该命令,实现下载某个网页,并用浏览器查看的功能 比如:下载网页新闻首页(http://news.163.com) scrapy view http://news.163.com完成后,会自动打开浏览器,并展示已经下载到本地的网页。 项目命令(1)bench 命令 可以测试本地硬件的性能, 会显示每分钟大约可以爬取多少个网页 (2)genspider命令 可以使用该命令来创建一个爬虫文件,这是一种快速创建爬虫文件的方式。 使用该命令可以基于现有的爬虫模板直接生成一个新的爬虫文件,同样需要在scrapy爬虫项目目录中,才能使用该命令。 scrapy genspider -l 使用该命令的-l 参数来查看当前使用的爬虫模板,如下图:
格式: scrapy genspider -t 模板 爬虫名称 "网站域名" 例如: scrapy genspider -t basic a "baidu.com" 创建了一个名称为a 的爬虫,爬取的网站是:http://www.baidu.com可以通过 -d参数实现查看某个爬虫模板的内容 scrapy genspider -d csvfeed(3)check命令 爬虫的测试比较麻烦,所以在scrapy中使用合同(contract : 也有翻译为契约,是一种交互式的检查方式)的方式对爬虫进行测试。 scrapy check 爬虫名 例如: scrapy check a执行完毕后,会出现如下图所示: (4)crawl 命令 可以通过这个命令来启动某个爬虫, 格式是: scrapy crawl 爬虫名(5)list 命令 可以列出当前可以使用的爬虫文件 格式: scrapy list(6)edit 命令 可以直接打开对应的编辑器对爬虫文件进行编辑, 该命令在windows中执行时会出现一点问题,改命令非常适合应用于Linux, 比如:要在Linux中使用edit命令来编辑某个爬虫文件,我们可以首先使用scrapy list先列出当前存在的爬虫文件,例:可以使用的爬虫文件是 abc,就可以直接使用下列命令: scrapy edit abc执行了该命令后,会自动调用对应的编辑器打开该爬虫文件。 (7)parse 命令 通过该命令,我们可以实现获取指定的url网址,并使用对应的爬虫文件进行处理和分析。 例如:获取百度首页(http:www.baidu.com) scrapy parse http:www.baidu.com --nolog由于这里没有指定爬虫文件,也没有指定处理函数,所以此时会使用默认的爬虫文件和默认的处理函数,进行相应的处理, scrapy parse -h 查看scrapy parse命令的参数,如下图:
以上参数主要分为两类: 普通参数(Options) 全局参数(Global Options) parse命令对应的参数表 参数含义- -spider=SPIDER强行指定某个爬虫文件spider进行处理-a NAME=VALUE设置spider的参数,可能会重复- -pipelines通过pipelines来处理items- -nolinks不展示提取到的链接信息- -noitems不展示得到的items- -nocolour输出结果颜色不高亮- -rules,-r使用CrawlSpider规则去提取回调的函数- -callback=CALLBACK,-c CALLBACK指定spider用于处理返回的响应的回调函数- -depth=DEPTH,-d DEPTH设置爬行深度,默认深度1- -verbose,-v显示每层的详细信息比如:如果想指定某个爬虫文件进行处理,可以使用--spider参数实现, scrapy parse http://www.baidu.com --spider=abc --nologh指定了abc爬虫文件,来对百度首页,进行处理,并且不输出日志信息 |
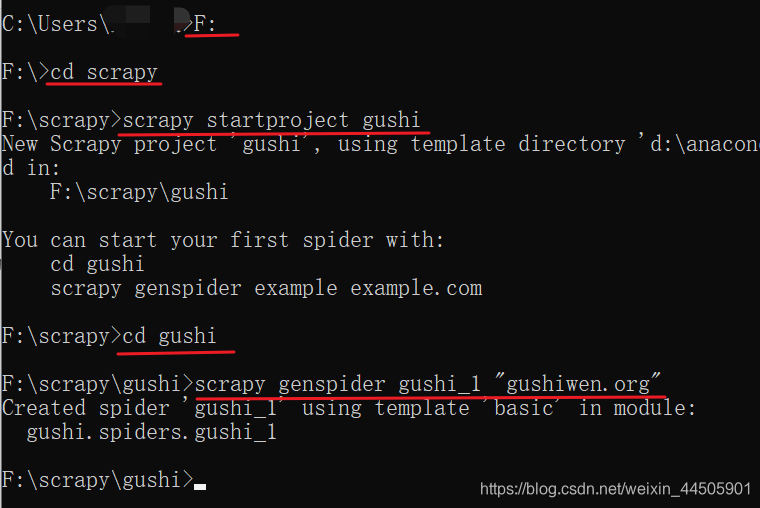 此时 F:\scrapy目录下就会出现创建好的 gushi文件夹
此时 F:\scrapy目录下就会出现创建好的 gushi文件夹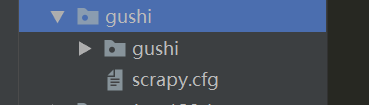 gushi 文件夹下有guoshi 子文件夹和scrapy.cfg 文件
gushi 文件夹下有guoshi 子文件夹和scrapy.cfg 文件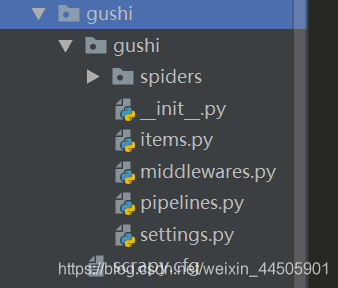 在spiders文件夹下
在spiders文件夹下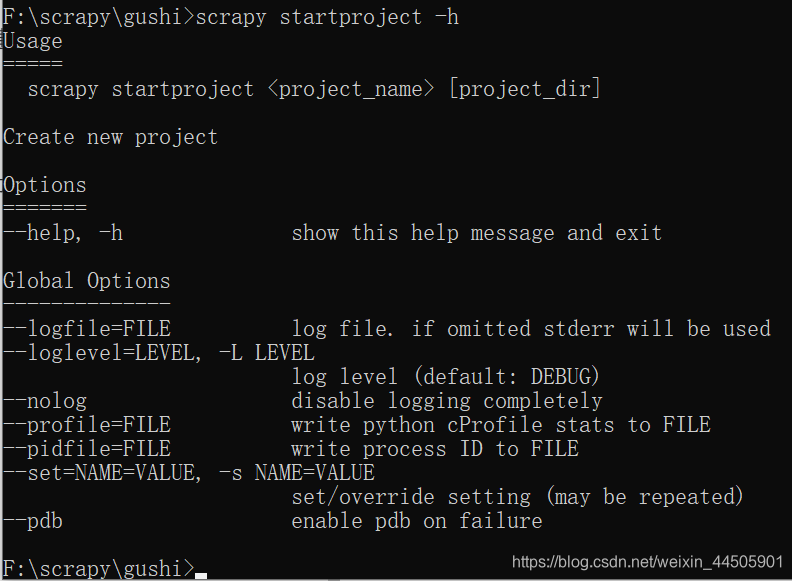
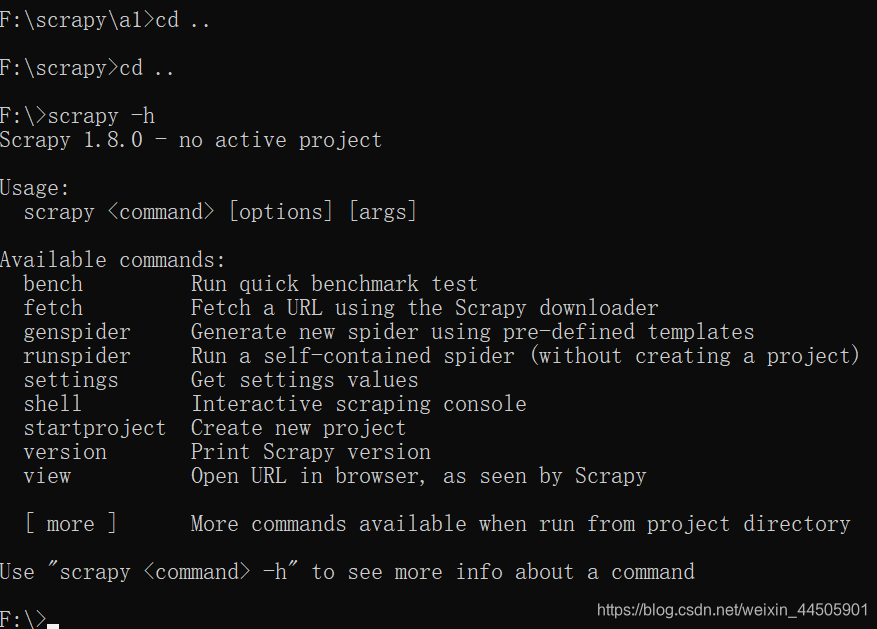 注意:其中 bench 命令比较特殊,归为项目命令
注意:其中 bench 命令比较特殊,归为项目命令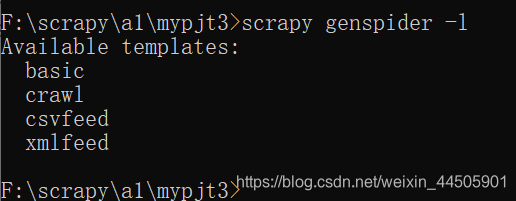 可以看到当前可以使用的爬虫模板有basic,crawl,csvfeed,xmlfeed 可以基于其中的任何一个爬虫模板来生成一个爬虫文件
可以看到当前可以使用的爬虫模板有basic,crawl,csvfeed,xmlfeed 可以基于其中的任何一个爬虫模板来生成一个爬虫文件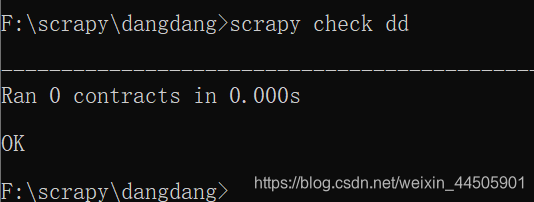 说明该爬虫文件的合同检查通过
说明该爬虫文件的合同检查通过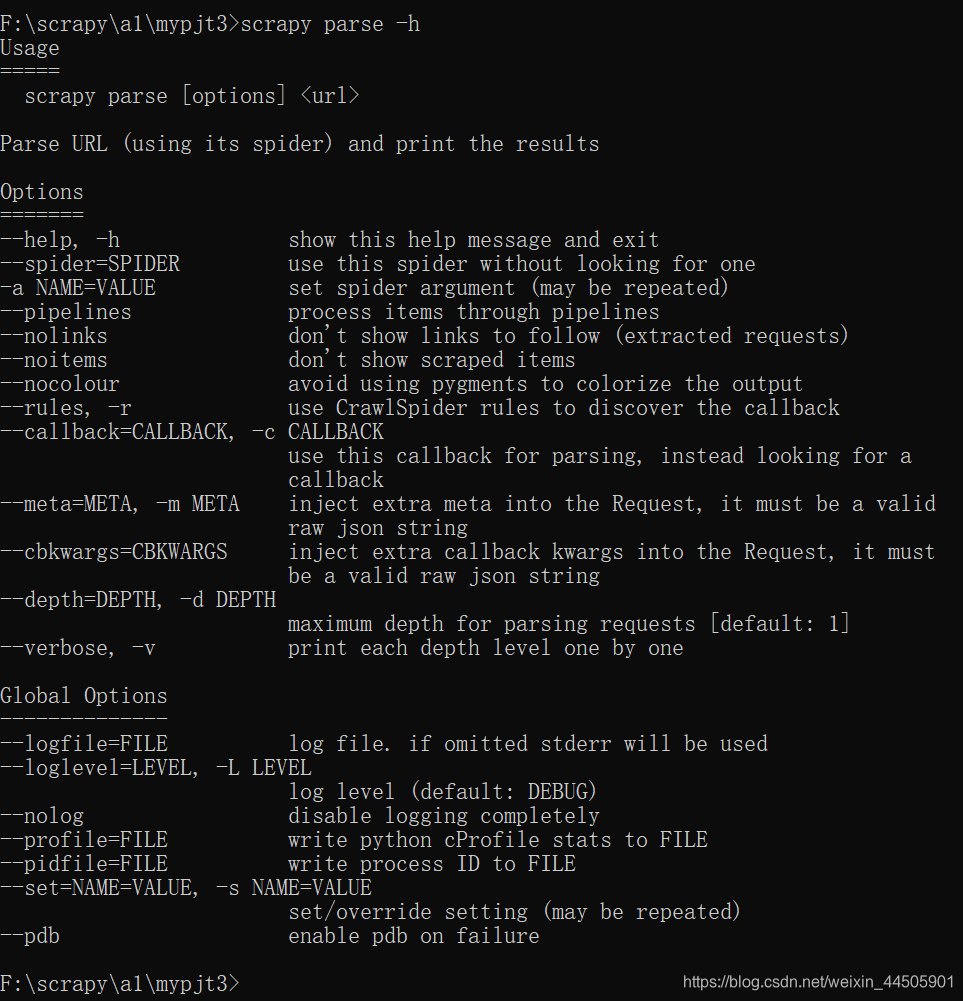
【本文地址】
今日新闻 |
推荐新闻 |